Zeitlicher Überblick
- 1912: Aufrufe in Zeitungen und Zeitschriften, mit denen Sammler angeworben wurden
- Aussenden der Fragebögen (sowie einer Belehrung) an diese Sammler, die wiederum Befragungen mit der einheimischen dialektkompetenten Bevölkerung durchführten
- 1913-1933: Haupterhebungen (sog. „große Fragebögen“)
- 1927-1937: Nacherhebungen („Ergänzungsfragebögen“)
- 1927-1990: Kundfahrten (kleiner Fragekatalog, bis 1965) sowie weitere Fragebucherhebungen (bis 1990)
- 1993-2011: Erstellung einer digitalen Belegdatenbank in TUSTEP
- 2016-2018: Konvertierung der TUSTEP-Daten nach XML/TEI
Der Hauptkatalog
Der Hauptkatalog
Die empirische Basis des Wörterbuchs der bairischen Mundarten in Österreich bildet der sog. „Hauptkatalog“, eine ca. 3,6 Millionen Belege umfassende Sammlung von Handzetteln. Diese besteht zum größten Teil aus indirekt erhobenem Material, das mithilfe von Sammlerinnen und Sammlern auf der Basis von 109 „großen Fragebögen“ (mit ca. 20.000 Detailfragen; vgl. Abbildung 1) sowie neun Ergänzungsfragebögen (vgl. Abbildung 2) in den Jahren 1913 bis 1937 zusammengetragen wurde. Die SammlerInnen waren dialektkompetente freiwillige Frauen und Männer aus dem gesamten Untersuchungsgebiet, die auf der Grundlage der ausgesandten Fragebögen Befragungen mit der einheimischen Bevölkerung durchführten. Zusätzlich erhielten die freiwilligen Mitarbeiterinnen und Mitarbeiter ein Exemplar der „Belehrung für die Sammler des bayrisch-österreichischen Wortschatzes“, in der die wichtigsten Informationen zur richtigen Handhabung der Handzettel sowie der korrekten Verwendung der dialektalen Lautschrift enthalten waren.
Ergänzt wurden die fragebogenbasierten Sammlungen durch direkte Erhebungen, die von geschulten DialektologInnen in der Form von Kundfahrten (1927 bis 1965) und Fragebucherhebungen (bis 1990) durchgeführt wurden.
Zusätzlich zu den empirisch erhobenen Daten wurden Exzerpte aus dialektologischer Fachliteratur (z. B. Dissertationen, Regionalwörterbücher) und anderen schriftlichen Quellen (wie Mundartsammlungen und historischen Texten) durchgeführt. Auf diese Weise konnten nicht nur Lücken im Belegmaterial gefüllt werden, sondern es fanden auch ältere deutsche Sprachstufen Eingang in die Datensammlung.
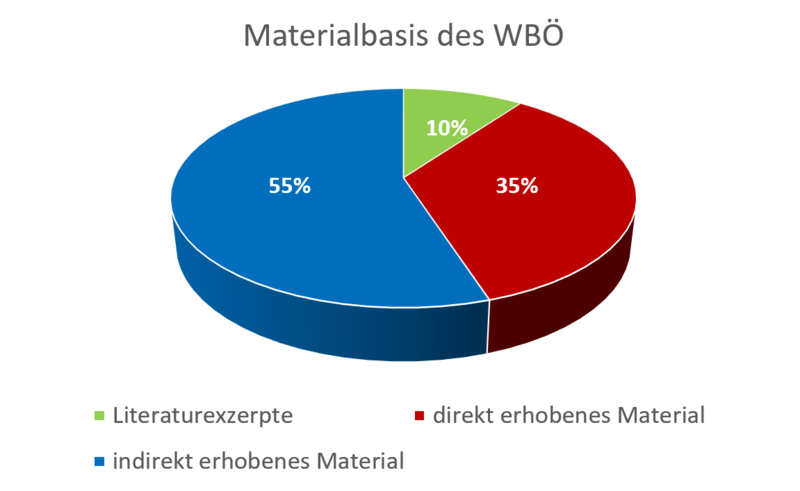
Abbildung 3 zeigt die Herkunft des WBÖ-Materials. Den größten Teil (55%) bildet das indirekt erhobene Material, das von den Sammlerinnen und Sammlern zwischen 1913 und 1937 zusammengetragen wurde. Das auf den Kundfahrten direkt erhobene Material stellt etwa 35% des Materialbestandes dar, während die Literaturexzerpte etwa 10% ausmachen.


Struktur der Belegdaten
Struktur der Belegdaten
Da das Material zum großen Teil von freiwilligen Sammlerinnen und Sammlern erhoben wurde, die zwar häufig mit großem Eifer ihre Arbeit erledigten, jedoch keine geschulten DialektologInnen waren und zudem das empirische Vorgehen in der ersten Hälfte des 20. Jahrhunderts nicht mit den heutigen Standards verglichen werden kann, weisen die Handzettel kein einheitliches Format auf, sondern unterscheiden sich teilweise in oft in vielen Details voneinander.
Zentrale Informationen für die Wörterbucharbeit sind Angaben zum Lemma, zur Bedeutung, zur Lautung und zum Herkunftsort, die sich auf den meisten Belegzetteln finden. Daneben enthalten die Zettel häufig auch grammatische Informationen (z. B. Wortart, Flexionsparadigma), Beispielsätze (häufig mit standardsprachlicher Übersetzung), Angaben zum Sammler, zum Fragebogen oder zur literarischen Quelle sowie etymologische Angaben. Zur Illustration von schwierig zu beschreibenden, „selteneren oder wichtigeren oder sonst merkwürdigen Gegenständen“ wurden häufig auch ergänzende Zeichnungen angefertigt.
Die folgende Auswahl zeigt einen kleinen Ausschnitt aus dem großen Variantenreichtum an Handzetteln.
Die Angaben zum Lemma in roter Schrift sowie Informationen zur Quelle bzw. zum Sammler/zur Sammlerin wurden von den Wörterbuchbearbeitern hinzugefügt, nachdem die Zettel in der Arbeitsstelle eingetroffen waren und lemmatisiert wurden. Wurde ein Zettel in die TUSTEP-Datenbank übertragen, erhielt er den Stempel „eingegeben“.

Digitalisierung des Handzettelkatalogs
Digitalisierung des Handzettelkatalogs
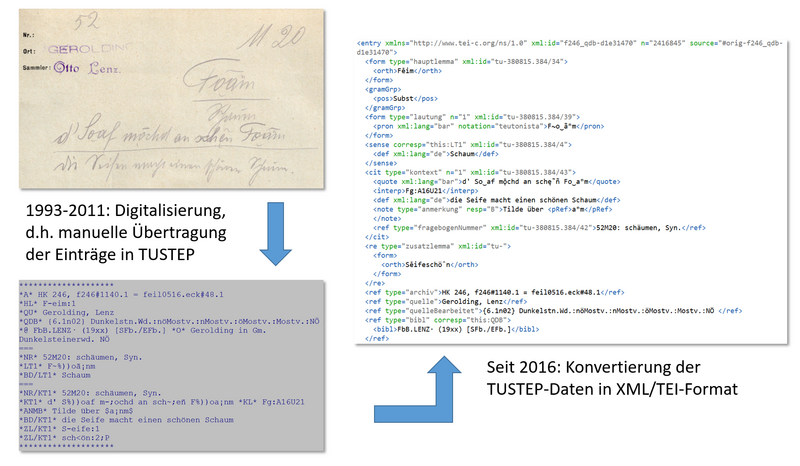
Um die lexikographische Arbeit zu erleichtern (d. h. etwa zeitaufwändiges Suchen und Sortieren von Belegen, Bedeutungen, etc. zu automatisieren), wurde im Jahr 1993 mit dem Aufbau einer digitalen Belegdatenbank begonnen. Zu diesem Zweck wurden die Belege ab dem Buchstaben D – die Buchstaben A bis C (inklusive P) waren bereits in den Artikeln verarbeitet worden – manuell in eine TUSTEP-Datenbank übertragen, deren Aufbau und Konzeption von den Institutsmitarbeitern erarbeitet wurde und die im Jahr 2011 schließlich fertiggestellt wurde.
Während TUSTEP zu Beginn der 1990er Jahre eine hervorragende Wahl zur digitalen Verarbeitung großer Textmengen darstellte, da es u. a. die Verwendung beliebig vieler diakritischer Zeichen erlaubte und sich sehr gut zur Erstellung von Druckvorlagen eignete, erwies es sich jedoch als nicht geeignet für die Anforderungen einer modernen, die Möglichkeiten des Internet ausnutzenden lexikographischen Arbeit. Zum einen handelt es sich bei TUSTEP um ein proprietäres Format, auf das nur in der TUSTEP-eigenen Sprache zugegriffen werden kann, zum anderen basiert es nicht auf den mittlerweile weit verbreiteten Unicode-Standards.
Im Jahr 2016 fand aus diesem Grund die erste Konvertierung des gesamten digitalen Hauptkatalogs aus TUSTEP in das plattformunabhängige Format XML/TEI statt. Das erste Resultat enthielt noch eine große Anzahl von Fehlern, die vor allem auf vorausgegangene, nicht mit den internen Codierungsregeln kompatible fehlerhafte Eingaben der Belegzettel in TUSTEP zurückzuführen waren. Für die lexikographische Arbeit war es daher nur eingeschränkt und übergangsweise zu verwenden. Diese Fehler wurden in einem aufwändigen und langwierigen Prozess von Sonja Schwaiger und Hans Derkits behoben, sodass seit Herbst 2018 eine weitgehend fehlerfreie und mit den Original-Handzetteln übereinstimmende Version der Datenbank im XML/TEI-Format existiert. Diese wird vom WBÖ-Team für die lexikographische Arbeit genutzt, steht aber auch über die LIÖ-Plattform externen Anwendern für verschiedene Suchabfragen zur Verfügung.